前两天需要完成一个扫描件转成 Excel 的操作,试了各种 OCR 软件效果都不理想,后来尝试了百度的文字识别 API,5 分钟搞定。看来广告说得对:“学会用 Python,比别人早下班 2 小时。” 🤷♂️
白嫖了好多次百度的 API,但是对各种基础知识都还一知半解,只会对着 Demo 改改。那么现在就从原理出发,花点时间查漏补缺一下吧。
API
API(Application Programming Interface,应用程序接口)是一些预先定义的函数,或指软件系统不同组成部分衔接的约定。用来提供应用程序与开发人员基于某软件或硬件得以访问的一组例程,而又无需访问源码,或理解内部工作机制的细节。——百度百科
所以 API 就是指把某些功能封装好,方便其他人调用。而调用的人可以很方便地使用这些功能,并且可以不需要知道这些功能的具体实现过程。
 调用 API 流程|CSDN
调用 API 流程|CSDN按照 百度智能云的文档,百度的 API 分为管控型 API(云产品创建、查看、启动停止、扩缩容、释放停止,类似于控制台)和功能型 API(百度语音、人脸识别、文字识别)。
插播一个 SDK 与 API 之间的关系:
你可以把 SDK 想象成一个虚拟的程序包,在这个程序包中有一份做好的软件功能,这份程序包几乎是全封闭的,只有一个小小接口可以联通外界,这个接口就是 API。 比如—— 有一杯密封饮料,它的名字叫做“SDK”。 饮料上插着吸管,吸管的名字叫“API”。 来自:SDK 和 API 的区别? - 简道云的回答 - 知乎
那么说回来,作为用户学习 API 调用的话,其实只需要关注两个部分,即上图中的“请求数据”和“处理并显示”部分,其他内容只管交给开发人员即可。
HTTP 请求
HTTP 的请求与响应,可以称为是 API 请求数据的载体。
按照定义来说,HTTP 就是在网络上传输 HTML 的协议,用于浏览器和服务器的通信。根据 HTTP 标准,HTTP 请求可以使用多种请求方法,其中 GET 和 POST 是最常见的 HTTP 方法。
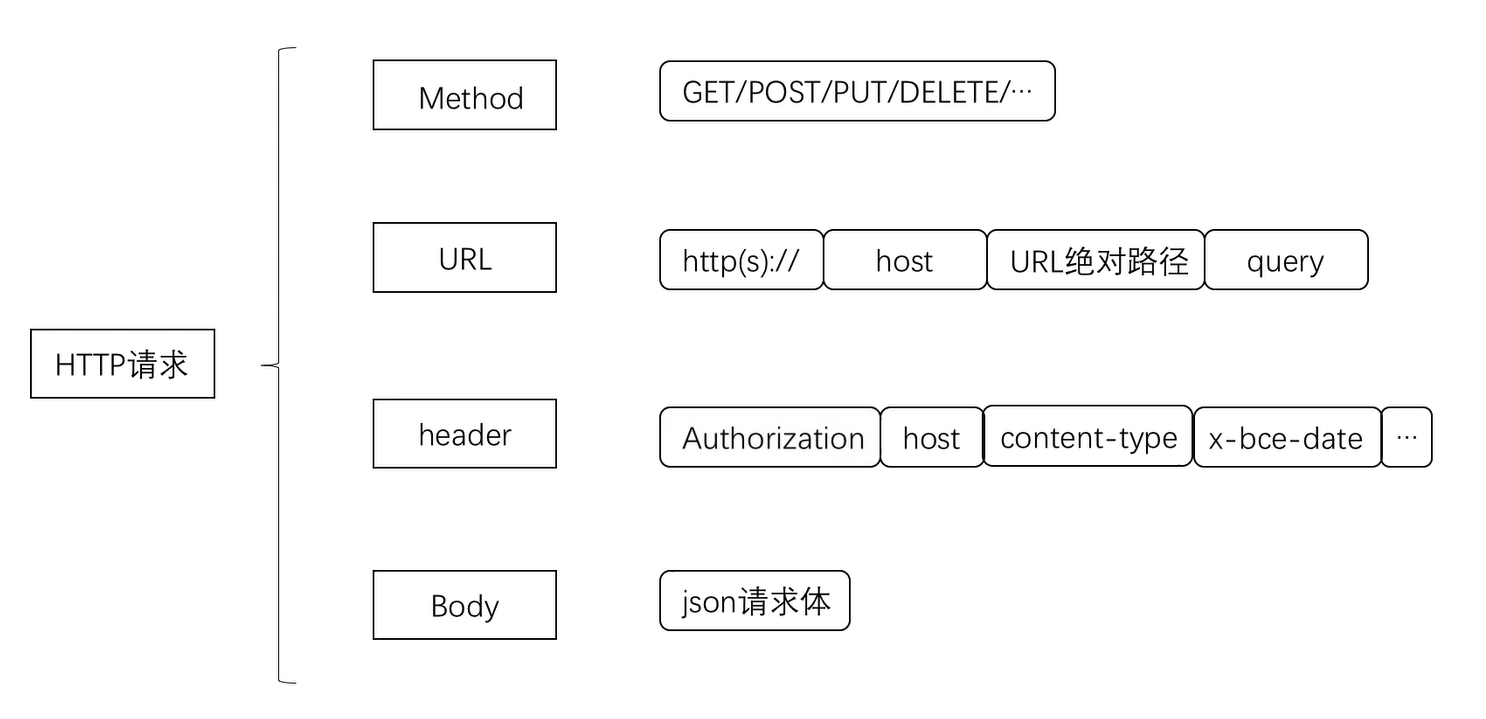 HTTP 请求
HTTP 请求对于调用 API 这个场景,分别解释一下 HTTP 请求的几个部分:
请求方法(POST、PUT 等),协议和域名(参考 API 文档)
URL 路径(其中的变量参考 API 文档中的请求参数),QueryString 查询字符串(以
?开始,用&连接多个查询字符串),请求头域(一般放鉴权、当前时间等,可能会写在文档的公共请求头里)鉴权(用 AK/SK 生成的 Authorization 认证字符串,可以参考百度的 教程,原理了解即可,后续有现成 Demo 可以抄)
 鉴权机制
鉴权机制- Body(JSON 格式,最关键的部分,例如需要识别的图片、需要翻译的文本,参考 API 文档修改)
获取 API
以百度 AI 开放平台为例,在官网找到想要使用的 API,注册、申请,在管理界面获取后文鉴权需要用到的 API_KEY/SECRET_KEY,然后就可以打开官方文档开始编写了。
 百度 AI 平台提供的服务
百度 AI 平台提供的服务Python 实现
以文字识别为例,百度给出了一个很详细的 QuickStart,对照着修改即可,这里简单过一下主函数流程。
首先导入一些模块
import sys
import json
import base64
# 保证兼容 python2 以及 python3
IS_PY3 = sys.version_info.major == 3
if IS_PY3:
from urllib.request import urlopen
from urllib.request import Request
from urllib.error import URLError
from urllib.parse import urlencode
from urllib.parse import quote_plus
else:
import urllib2
from urllib import quote_plus
from urllib2 import urlopen
from urllib2 import Request
from urllib2 import URLError
from urllib import urlencode
# 防止 https 证书校验不正确
ssl._create_default_https_context = ssl._create_unverified_context
然后是一些关键字符串,这里需要根据之前获取的 AK/SK、不同 API 的 URL 进行修改,示例中填充的是一个文字识别的例程。
API_KEY = 'GmhC18eVP1Fo1ECX911dtOzw'
SECRET_KEY = 'PQ2ukO4Aec2PTsgQU9UkiEKYciavlZk8'
OCR_URL = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"
TOKEN_URL = 'https://aip.baidubce.com/oauth/2.0/token'
鉴权流程,后续使用的时候照抄即可。
def fetch_token():
"""
获取 token
"""
params = {'grant_type': 'client_credentials',
'client_id': API_KEY,
'client_secret': SECRET_KEY}
post_data = urlencode(params)
if (IS_PY3):
post_data = post_data.encode('utf-8')
req = Request(TOKEN_URL, post_data)
try:
f = urlopen(req, timeout=5)
result_str = f.read()
except URLError as err:
print(err)
if (IS_PY3):
result_str = result_str.decode()
result = json.loads(result_str)
if ('access_token' in result.keys() and 'scope' in result.keys()):
if not 'brain_all_scope' in result['scope'].split(' '):
print ('please ensure has check the ability')
exit()
return result['access_token']
else:
print ('please overwrite the correct API_KEY and SECRET_KEY')
exit()
用二进制方式读取需要识别的文件,加入 HTTP 请求内容。
def read_file(image_path):
"""
读取文件
"""
f = None
try:
f = open(image_path, 'rb')
return f.read()
except:
print('read image file fail')
return None
finally:
if f:
f.close()
HTTP 请求,这里用的是 Python 的 urllib 库中的 Request 函数,据说更方便的方案是使用 requests,一个 Python 第三方库,处理 URL 资源特别方便。
def request(url, data):
"""
调用远程服务
"""
req = Request(url, data.encode('utf-8'))
has_error = False
try:
f = urlopen(req)
result_str = f.read()
if (IS_PY3):
result_str = result_str.decode()
return result_str
except URLError as err:
print(err)
主函数,鉴权、打包、请求、解析。
if __name__ == '__main__':
# 获取 access token
token = fetch_token()
# 拼接通用文字识别高精度 url
image_url = OCR_URL + "?access_token=" + token
text = ""
# 读取书籍页面图片
file_content = read_file('./test.jpg')
# 调用文字识别服务
result = request(image_url, urlencode({'image': base64.b64encode(file_content)}))
# 解析返回结果
result_json = json.loads(result)
for words_result in result_json["words_result"]:
text = text + words_result["words"]
# 打印文字
print(text)
百度 AI 开放平台有各种功能型 API 可以免费调用,玩得开心。