Course website: http://rail.eecs.berkeley.edu/deeprlcourse-fa18/
Video link: https://www.youtube.com/playlist?list=PLkFD6_40KJIxJMR-j5A1mkxK26gh_qg37
第一讲
课程简介 材料、助教、先修课程、课程作业(提供 TensorFlow 框架)
什么是强化学习? 为什么要研究它?14'00
更大的问题,怎么建立一个智能机器?
快速响应、复杂规划没问题,但缺少扩展性、适应性。
人类的灵活性和适应能力是对机器来说复杂且多样的挑战。
深度学习 → 非结构化环境18'23
处理输入信息,但没有解决决策问题。
强化学习 → 决策的数学形式
decisions(actions)
consequences(observations、rewards)
e.g. TD gammon 双陆棋 AlphaGO 游戏 机器人运动技能学习 抓取
**何谓 deep?**用 CV 举例22'30
传统 CV:手动设计的特征,真正的学习只发生在最后一层分类器
deepCV:每一层经过端到端训练,适应性
传统 RL:手动提取特征(困难 受限)
deepRL:端到端训练
端到端对做决策有什么用?27'00
感知系统、控制系统,如果分开设计,联合优化,中间很多特征是不关心的。
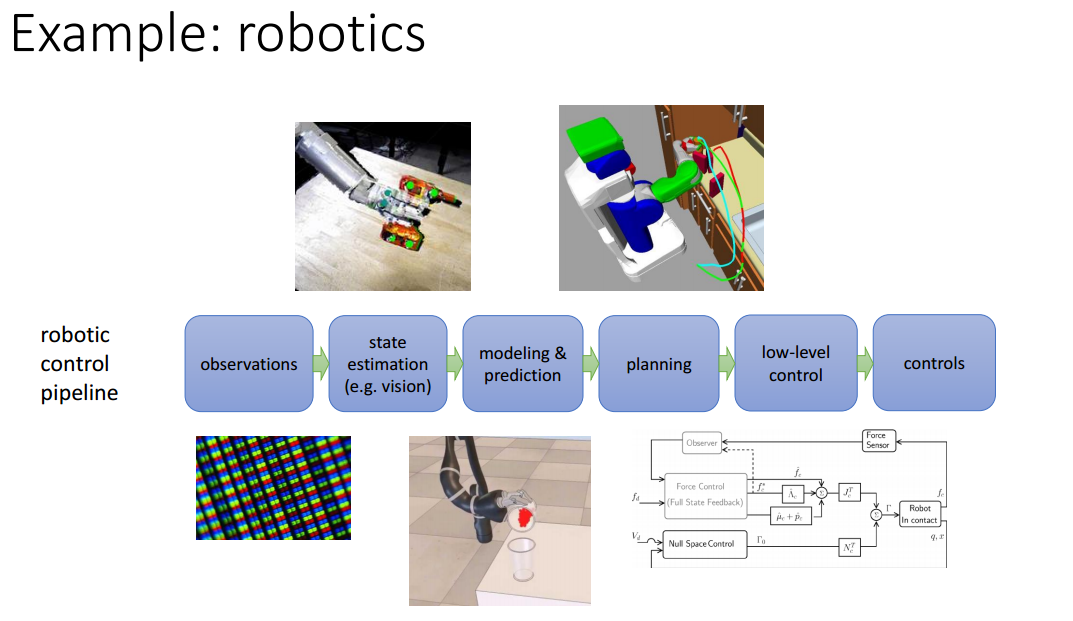
一个机器人控制的例子29'14
观测 状态估计 建模&预测 规划 低等级控制 控制
中间要考虑很多东西,很多假设,最后的系统就会有很多限制。
举例 decisions 和 consequences31'59
狗狗:actions 肌肉收缩(运动或发出声音);observations 各种感官;rewards 食物
机器人:actions 电机电流;observations 相机图像;rewards 任务成功标准
仓库:actions 买什么;observations 库存水平;rewards 利润
强化学习是很多机器学习问题的泛化表示。36'34
Deep model 就是解决复杂问题的关键。
应用在交通上的一个例子,一辆自动驾驶的车抑制全局交通堵塞。
扩展问题 从数据中归纳出奖励函数 模型在不同问题之间转换(迁移学习) 尝试预测
奖励 游戏有得分,但是在现实中没有。 可以推断,可以模仿,可以迁移。 e.g. 模仿学习 用于自动驾驶 e.g. 基于模型 进行预测 预测真实的物理环境
回到开头,怎么建立一个智能机器?56'30
模仿人类,复现各个部件。
实际上人的学习能力很强,所以让机器学习。
或许只需要单一算法(而不是拆分),有实验证明不同感官之间的处理机构可能互通。
这个算法需要什么:很多输入很多输出。
深度强化学习:深度——处理复杂感官输入;强化学习——数学理论支持。
现在的 DRL 能做到什么?66'00
在有特定规则的世界下完成任务,如游戏、下棋。
从原始传感器数据中学到简单技能,如抓取。
从足够的专家数据中模仿学习,如自动驾驶。
现在的挑战在哪里? 学习速度太慢太慢太慢。 不能使用过去的经验。 奖励函数不明确。 是否需要模型。
Alan Turing Quote: “Instead of trying to produce a programme to simulate the adult mind, why not rather try to produce one which simulates the child’s?”
第二讲 模仿学习
今天会讲作业 1 下周三讲座 关于 TensorFlow
模仿学习 3'26
在一个监督学习任务中,输入 o(observation),输出 a(action),策略π是在 o 上的条件分布,π有一些参数θ。
神经网络真正做的事情是将概率分布参数化。
过渡到序列化问题,所有参数加一个下标 t。
或许输出 a 是连续行为的分布,比如设计成高斯分布的期望与方差。
状态 s,是一个隐含的状态。举例,o 是图片像素序列,s 是图中物体状态,状态可能不能被推断(某一刻被挡住了)。
p 是转移函数
当前状态只与上一状态和动作有关 → 马尔科夫性。但过去的观测可能会对当前观测有帮助。
 aside:控制论中用 x 表示状态,u 表示行为。
aside:控制论中用 x 表示状态,u 表示行为。
行为克隆,简单的监督学习。16'44
Does it work? No!
误差累计,出现了不在训练集中的状态。
这篇论文提出的一种技巧(自动驾驶),使用三个摄像头,训练的时候把左侧的图像对应的转向向右偏一些。
或者可以引入噪声,给出全分布。
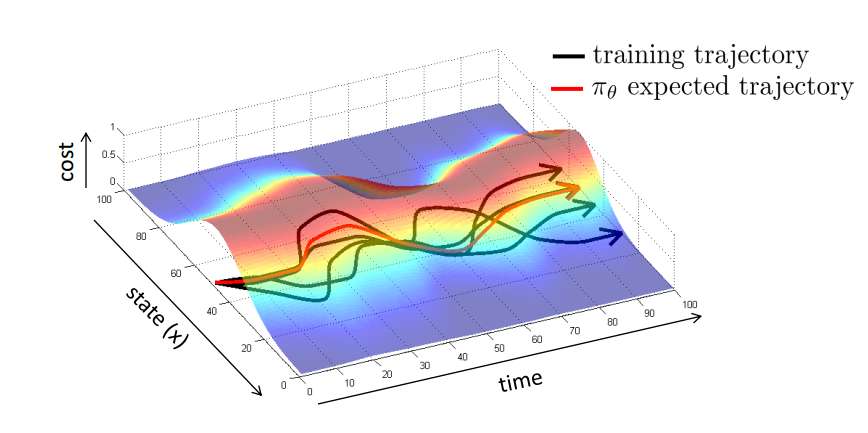
Dataset Aggregation30'50
不能使训练完美无误差,那就在数据集上做文章。
1、用人类数据集 D 训练π
2、使用π输出 Dπ
3、给 Dπ打标签
4、数据集混合
Q:直接替换原有 D?
A:可以试试,效果不好。
Q:一开始随机可以吗?
A:可以,也能收敛。
问题在于第三步耗费大量资源。人类的行为可能是非马尔科夫(决策受到历史影响),或者多模态(受心情影响)。
非马尔科夫42'19
递归神经网络使用历史信息,有点积分器的感觉。
多模态43'40
左右都可,但是不能平均。离散的话加 softmax,连续的话:输出混合的高斯分布;使用隐变量模型,在输入的时候添加一个随机数,但是让网络利用噪声需要一些技术;自动回归离散化(每次离散一个维度?)。
Case study55'30
头盔采集数据使无人机在森林小径中巡逻;循环性和多模态的网络用于机器人抓取;低成本实现机械臂任务。
Other topic 结构化问题;逆强化学习 人类提供的数据是有限的;有些不能示范;机器不能自我学习
术语和记号 c 成本函数(控制论)r 奖励函数(强化学习)一个意思
一些数学分析71'00
考虑在 T 时间内,假设遇到训练集中的情况,算法都会有一个上限,连续时间后损失是指数形式。
第三讲 TensorFlow
回顾一下上节课没讲完的
为了超越模仿学习,需要定义一个目标函数(奖赏或损失)
一种做法是在状态上专家选择的任何动作的对数似然概率
为了将训练分布和数据集分布联系起来,假设一个 Pmistake,有以下推导(没看懂)。大致意思是如果分布不同,最后的误差会是 T 平方增长。
 奖励函数很复杂,是因为探索空间可能会很大。
奖励函数很复杂,是因为探索空间可能会很大。
接下来主要讲 TensorFlow 22'22
p.s. 老师用的是 Google Docs 放映
TensorFlow Overview
goal: train an agent(智能体) to perform useful tasks.
定义计算图 computation graphs 计算梯度下降 calculating gradients
What is Tensorflow 首先需要定义 session,理解成一张白纸。 定义常量输入,定义运算,使用 tf.Session().run() 执行,让数据在图中流动,完成运算。
How to input data 使用 placeholder 占位符进行数据输入,同时也可以不指定占位符 shape,用于不同大小的数据(batch size)。
How to perform computations Easy peasy. 维数不同的时候会尝试广播操作(broadcasting),所以计算时要小心维数。 符号、*元素乘(点乘),matmul 矩阵乘(叉乘)。 有时间去翻一翻 TensorFlow 的官方 API。
How to create variables 初始化所有变量
init_op = tf.global_variables_initializer()
sess.run(init_op)
How to train a neural network for a simple regression problem 训练一个简单的回归问题 每一层的变量包括权重 w 和偏置 b;共三层,使用 relu,回归问题输出层不需要激活函数。
57'53-61'58聋了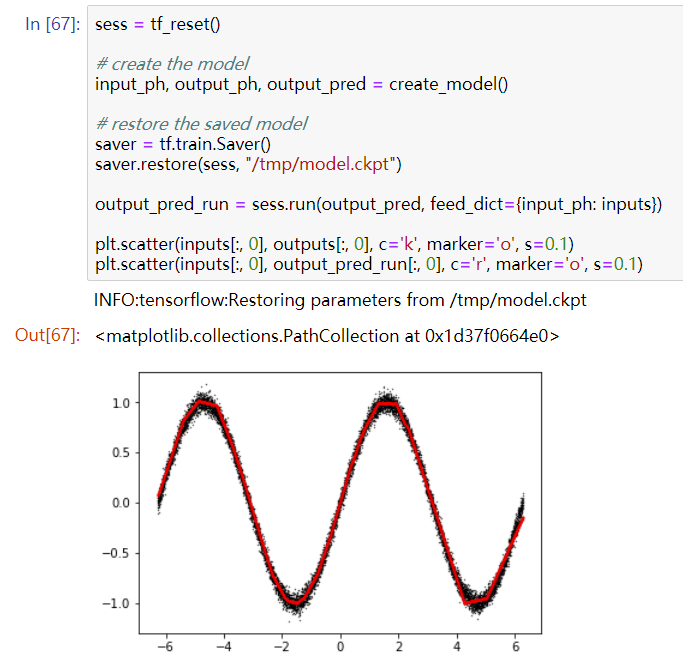
Tips and tricks 检查维数 检查变量 使用 Keras 这种高级 API 变量范围
tf.variable_scope
第四讲 强化学习简介
下周三作业一截止 大作业鼓励自己选题 但有指导文件
本节课内容 一些高层概念性知识 马尔科夫决策过程的定义 强化学习问题的定义 典型强化学习算法的结构 anatomy 不同种类的强化学习算法综述
定义 3'54
顺序决策问题 sequential decision problem
包括输入 observation 输出 action 策略 policy
policy 就是要学习的 对给定输入关于输出的条件分布
即 conditional distribution 输出 given 输入
state 满足马尔科夫随机过程 (satisfy the Markov property)
observation 不满足
奖励函数 6'40
r(state, action)
注意是选择全局最大值 而不是当前最大值 optimize the reward overall time
马尔科夫链 8'33
状态 state 和条件概率分布 p(conditional probability distribution)

马尔科夫决策过程 11'40
状态 state 和转移算子 transition operator
加入行动空间和奖励函数
奖励函数是定义在状态和行动空间上的叉积
当状态只能部分观察→partially observed Markov decision process
还需要添加一个观察空间和输出概率(给定 state 的 observation 的条件概率)
举例:state 是车的位置和速度 action 油门刹车方向盘 observation 摄像头获取的图片
强化学习的目的 16'00
用一个神经网络显式表示策略 或用价值函数隐式表示 总之有一个θ参数
链式法则计算概率
过渡到无限长 会达到稳态分布吗? 变成一个等式 变成了特征值为 1 的特征向量问题 可以证明这要求可逆性 奖励函数需要除以 T 举例:正确的房间奖励 1000 错误的房间奖励-1 因此不仅能到而且会尽快到
对于不可微的情况也能用强化学习的原因 29'50
算法 32'44
三部分:产生样本 拟合模型/估计反馈 优化策略
model-based RL 基于模型的强化学习
backprop through 反向传播
很基础 但不常用
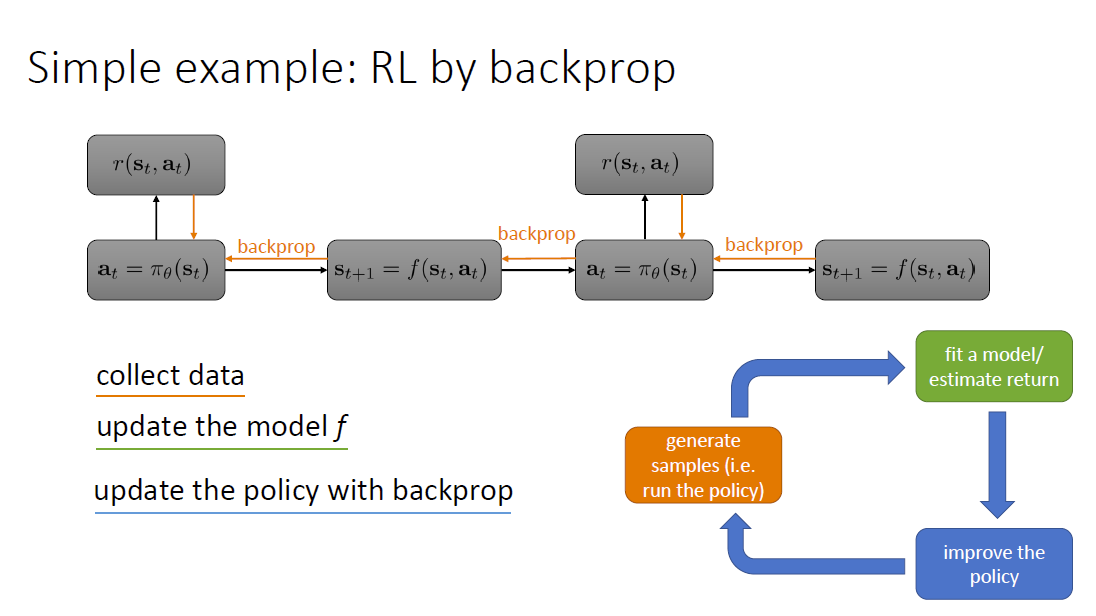
哪部分更 expensive? 真实环境中收集数据受到物理限制 计算反馈和特定算法有关 计算梯度反向传播也和算法有关
为什么不够好? 只针对确定性环境、确定性策略、连续状态、难以优化(梯度爆炸、梯度消失) exploding or vanishing gradients
处理随机系统 44'21
Q 奖励函数
重点
Review 54'03 马尔科夫定义 强化学习的目标 算法基本结构
不同种类的强化学习算法 58'52
策略梯度算法 policy gradients
基于值的算法 value based
动作-批评算法 actor-critic
基于模型的算法 model-based
权衡 tradeoffs 66'30
样本需求量
稳定性易用性
系统是随机的/确定的
系统连续/离散
有限无限
等等
关于样本效率 on-policy off-policy 每次更新完是否需要重新生成样本
监督学习时 总会收敛 强化学习 不都会收敛
Examples 80'35