AprilTag 是一个视觉基准库,在 AR、机器人、相机校准领域广泛使用。通过特定的标志(与二维码相似,但是降低了复杂度以满足实时性要求),可以快速地检测标志,并计算相对位置。
第一次接触 AprilTag 是去年智能车室内对弈组的时候了,那时候使用的摄像头硬件是 OpenMV,官方库里就集成了 AprilTag 的识别,在已知相机内参的情况下,单个 AprilTag 就能实现三维空间内的位姿定位。
虽然和 QR 码很像,但 AprilTag 视觉基准码有完全不同的目标和应用场景。使用 QR 码时,通常需要将摄像头与标签对齐,然后以相当高的分辨率拍摄它,获得数百个字节,比如一个网址;相比之下,视觉基准码只承载很小的信息(也许是 12 位),但即使它的分辨率非常低、光线不均匀或隐藏在图像的角落里,也能被自动检测和定位。
官网:https://april.eecs.umich.edu/software/apriltag.html
原理
AprilTag 团队主要的论文有两篇:
- ICRA 2011 - AprilTag: A robust and flexible visual fiducial system
- IROS 2016 - AprilTag 2: Efficient and robust fiducial detection
下文从检测器、编码系统两部分过一下原理(其实就是翻译原文)。
使用自然出现的特征一直是机器感知的重点,但人造特征在一些实验中也扮演了很重要的角色,可以简化一些并不关注自然特征的系统。论文设计了一种使用二维码的视觉基准系统,可以从单张图像中实现六个自由度上的定位。这一系统融合了之前的直线检测、数字编码技术,对遮挡、扭曲、镜头失真有更好的效果。
检测器
检测器设计为很低的假阴率,所以就有一个很高的假阳率。(真假表示识别正确与否,阴阳表示识别的结果是真或假,这里就是尽量不漏掉可能的矩形)编码系统会补偿这一过高的假阳率。
- 直线检测
计算像素的梯度→按照梯度大小排序→以梯度方向作为约束进行聚类→最小二乘计算直线
第一步是从图像中检测直线,方法与 ARTag 检测器的基本方法相似,计算每个像素点的梯度方向和梯度大小,并将像素点聚类成梯度方向和梯度大小相似的分量。 该聚类算法类似于 Felzenszwalb 的基于图的方法:创建一个图,每个节点代表一个像素;在相邻像素之间添加边,边权等于像素在梯度方向上的差值。然后将这些边按边权递增的方式进行排序处理:对于每条边,我们测试其两侧像素所属的集群是否应该连接在一起。
假设一个集群 n,我们把其中像素梯度方向的范围记为 D(n),梯度大小的范围记为 M(n)。也就是说,D(n) 和 M(n) 是标量值,分别表示梯度方向和梯度大小的最大值和最小值之差。对于 D(),必须小心处理 2π周期。然而,由于有用的边的跨度要比π小得多,这就很简单了。
给定 n 和 m 两个集群,如果满足以下两个条件,我们将它们连接在一起: $$D(n \cup m) \leq \min (D(n), D(m))+K_{D} /|n \cup m|$$ $$M(n \cup m) \leq \min (M(n), M(m))+K_{M} /|n \cup m|$$ 这条件可以直观理解:D() 和 M() 值小,表示分量内部变化小。如果两个集群联合起来后的 D() 和 M() 值,与单独的集群差别不大,则将它们连接在一起。参数 KD、KM参数允许分量变化范围适度增加,但随着集群变大,这种裕度会迅速缩小。
- 矩形检测
深度优先搜索→按逆时针顺序考虑线段组合→二维查找表加速
此时,已经为图像计算了一组有向线段。下一个任务是找到一系列的线段,形成一个矩形,同时对于遮挡和噪声尽可能健壮。
我们的方法基于深度为 4 的递归深度优先搜索:搜索树的每一层都向矩形添加一条边。在深度 1,我们考虑所有的线段。在深度 2 到 4,我们考虑这些线段:它们的起点和上一个线段的终点足够“接近”,且遵循逆时针的旋转顺序。通过调整“接近”的阈值来实现对遮挡和分割错误的健壮性。
一旦找到了四条线段,就可以创建一个候选的矩形,这个矩形的顶点是组成它的线的交点。因为这些线段是用来自多个像素的数据拟合的,所以顶点的精度能在一个像素以内。
- 单应性变换和外参估计
我们计算一个 3×3 的单应性矩阵,which 能将二维点从标签坐标系中以齐次坐标投影到二维图像坐标系。这一步是利用直接线性变换 (DLT) 算法计算。这一部分算法还没看明白。
- 有效负载解码
动态阈值
最后一个任务是从有效负载字段读取比特位。我们通过计算每个比特在标签坐标上的位置,使用单应性变换将其转换到图像坐标下,然后对结果像素进行阈值处理来实现。为了增强对光照的健壮性,我们使用了一个空间变化的阈值。(不仅仅是不同标签之间的光照变化,同一个标签的不同位置光照也可能不同)
具体来说,我们建立了“黑色”像素强度的空间变化模型,以及另一个“白色”像素强度的模型。我们使用标签的边界(其中包含已知的白色和黑色像素),来学习这个模型。我们使用以下强度模型:
$$ I(x, y)=A x+B x y+C y+D $$
该模型有 4 个参数,用最小二乘回归很容易计算。我们建立了两个这样的模型,分别给黑白两色。解码数据时使用的阈值就是黑白模型预测强度值的平均值。
编码系统
命名规则→考虑四个旋转方向的唯一性→去除具有混淆性的码→考察码的矩形覆盖复杂度
一旦数据从正方形中解码出来,就要靠编码系统来检查其有效性。编码系统的目标是:最大化可识别码的数量;最大化可检测到或纠正的比特位错误;最小化假阳性/标签间混淆率;最小化每个标签的总比特数(因此缩小标签的大小)。
这些目标常常是相互冲突的,因此每一种方案都代表了一种权衡。在本节中,我们建议使用一个修改的 lexicodes。经典的 lexicodes 是由两个常量参数化的:每个码字的比特数 n 和任意两个码字之间的最小汉明距离 d。lexicodes 可以校正 (d-1)/2 位错误,检测 d/2 位错误。为了方便起见,我们将最小汉明距离为 10 的 36 比特编码表示为 36h10 码。
提到汉明距离,推荐一下 3B1B 的视频 【官方双语】汉明码 Pa■t1,如何克服噪■,非常精彩。
lexicode 的名称来源于用于生成有效码字的启发式:候选码字按照字典顺序(从最小到最大)考虑,当它们与之前添加到码本的每个码字至少有 d 的距离时,将新码字添加到码本中。虽然很简单,这种方案往往是非常接近最优的。
在视觉基准系统的应用情况下,编码方案必须对旋转具有健壮性。换句话说,当标签旋转 90 度、180 度或 270 度时,它与其他代码的汉明距离仍然是 d。标准的 lexicode 生成算法不能保证此属性。然而,标准生成算法可以简单地扩展来支持这一点:在测试一个新的候选码字时,简单地确保所有四次旋转都有所需的最小汉明距离。lexicode 算法可以很容易地添加约束,这是我们方法的一个优点。
一些码字,尽管满足汉明距离限制,却是糟糕的选择。例如,由所有零组成的码字将生成一个看起来像单个黑色方块的标记。这种简单的几何图形经常出现在自然场景中,导致假阳误报。我们没有手动识别有问题的码,而是通过拒绝简单几何模式的候选码来修改 lexicode 生成算法。我们的度量是基于生成标签的 2D 图案所需的矩形数。例如,一个全黑的码只需要一个矩形,而黑-白-黑条纹需要两个矩形(一个大的黑色矩形加上第二个较小的白色矩形)。我们的假设是,复杂度高的标签模式(需要重构许多矩形)在自然界中出现的频率较低,从而导致假阳性率较低,本文后面的实验结果也支持了我们的假设。
利用这个思想,我们再次修改 lexicode 生成算法,以拒绝过于简单的候选码。我们使用一种简单的贪婪方法来近似估计标签码所需的矩形数量,这种方法反复考虑所有可能的矩形,并添加能够最大程度减少误差的矩形。由于标记通常非常小,所以这种计算不是瓶颈。复杂度小于阈值(在我们的实验中通常为 10) 的标签将被拒绝。
 定制的几片 PVC 材料的 AprilTag
定制的几片 PVC 材料的 AprilTag原文中的实验结果分析这里略去。
第二代整体思路不变,主要是在原有检测器的基础上进行了改进,不再花时间关注部分遮挡的标签(因为即使检测出来大概率也无法解码),修改了算法,降低了误报率,提高了检测率,减少了检测所需的计算时间。同时还开发了适用于 iOS 设备的 APP,可在 App Store 上免费下载。
 AprilTag APP 界面
AprilTag APP 界面代码
这次主要参考了 rain 同学 的代码 Apriltag_python,他在 Python 上复现了 AprilTag 系统,并作为他的毕业设计。具体使用的算法和论文中有一些差距,但最终效果也很不错。
用于机器人标定
受到 KeyPose: Multi-View 3D Labeling and Keypoint Estimation for Transparent Objects 启发,想把 AprilTag 应用到机器人手眼标定上。
下面引用一段 YouTube 视频,或者可以查看微信推送:[谷歌提出位姿估计新算法 KeyPose, 基于立体视觉有效估计透明物体的 3D 位姿 (https://mp.weixin.qq.com/s/0Nc2s4OFw8Jr-lELbGywbQ)
在图中可以看到,研究人员使用了 AprilTags 来精确地追踪相机在拍摄过程中的位姿。人们只需要手工标注每一段视频中很少一部分图像中的 2D 关键点,就可以基于多视图几何从视频中的所有帧里抽取出 3D 关键点的信息,以百倍的量级提升了数据集的构建效率。
 基于机械臂的自动化图像序列采集装置
基于机械臂的自动化图像序列采集装置对于上述这种“眼在手上”的安装方式,使用 AprilTag 进行辅助定位可以说是一个非常合理的解法。之前使用过一些手眼标定的算法,且不谈精度,操作起来的步骤就十分繁琐,而且实验中还需要时刻注意不要碰撞了相机,相机的一点点角度变化就可能需要重新标定。
在最近的机器人抓取实验中,我使用了 RGBD 相机作为视觉输入,选择的是“眼在手外”的安装方式,计划绕过手眼标定,使用 AprilTag 实现相机坐标系与机器人坐标系的配准。
假定相机垂直于待抓取平面(可以利用深度图进行辅助安装),那么相机坐标系与机器人坐标系的 z 轴就已经平行,将剩下的 xy 平面的变换定义为一次仿射变换,因此需要三组对应的坐标点对进行计算。
所以设计的操作方式为:在待抓取平面上设置三个 AprilTag(位置随意),然后利用机器人的拖动示教功能,移动机器人工具手末端依次触碰每个 AprilTag 的中心,上位机分别记录下三次机器人坐标。之后开启相机(位置随意)进行 AprilTag 的识别与定位,利用得到的这三个坐标对进行仿射变换,就能实时进行坐标系配准。
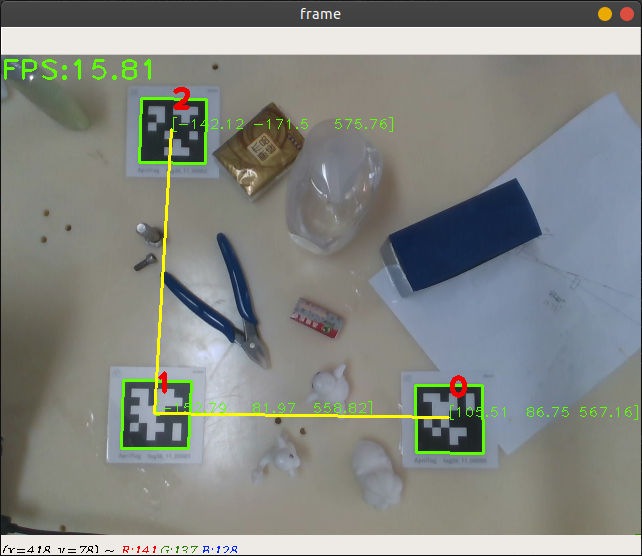 AprilTag 标定效果
AprilTag 标定效果最后效果不错,下次更新整体视频。