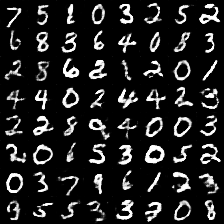使用 TensorFlow 在 MNIST 数据集上实现一个生成式对抗网络。
开头先推荐一些教程及资料:
【推荐👍】GAN 入门教程 从 0 开始,手把手教你学会最火的神经网络 https://cloud.tencent.com/developer/article/1078628
【莫烦】生成对抗网络 https://morvanzhou.github.io/tutorials/machine-learning/ML-intro/2-6-GAN/
【官方】深度卷积生成对抗网络 TensorFlow Core https://www.tensorflow.org/tutorials/generative/dcgan?hl=zh-cn
CNN
CNN 最早可以追溯到 1968 年 Hubel 和 Wiesel 的论文,这篇论文讲述猫和猴的视觉皮层含有对视野的小区域单独反应的神经元,如果眼睛没有移动,则视觉刺激影响单个神经元的视觉空间区域被称为其感受野(Receptive Field),这为 CNN 的局部感知奠定了一个基础。然后是 1980 年,神经感知机 (neocognitron) 的提出,标志了第一个初始的卷积神经网络的诞生,也是感受野概念在人工神经网络领域的首次应用,神经认知机将一个视觉模式分解成许多子模式(特征),然后进入分层递阶式相连的特征平面进行处理。
CNN 由输入和输出层以及多个隐藏层组成,隐藏层可分为卷积层,池化层、RELU 层和全连接层等。
输入层
CNN 的输入一般是二维向量,可以有第三维高度,例如 RGB 图像有三个通道。
卷积层
卷积层是 CNN 的核心,层的参数由一组可学习的卷积核组成。在前馈期间,每个滤波器对输入进行卷积,计算滤波器和输入之间的点积,并产生该滤波器的二维激活图,提取更高层次的特征。
为了理解卷积,可以联想到在信号与系统中,输入对一个系统的响应是等于输入信号 e(x) 与系统函数 h(x) 进行卷积,h(x) 可以看作一个滤波器,它会对输入信号进行筛选,选择和它类似的信号;类似的,在数字图像处理中,可以使用 sobel 算子提取图像边缘特征,这是因为 sobel 算子与图像边缘的结构相似,所以进行卷积之后就能提取出来。不同的是,CNN 中的卷积核参数未知,即特定模式未知,是需要学习的参数。
值得一提的是,在下文的 GAN 中,还出现一种逆卷积,其输入比输出更小,看起来信息量变多了,实际上信息是从卷积核中来的。举例来说,特征向量描述了一张图中哪里有眼睛,而对应就有一个卷积核告诉网络眼睛怎么画出来。
卷积是特征的提取,反卷积就是特征的恢复,因此也可以理解成一种逆运算。
关于具体的计算方法,可以找一些 Gif 理解一下。
池化层
池化层又称下采样,它的作用是减小数据处理量同时保留有用信息。例如,将图像分割成 2×2 的小块,每块中只保留最大值(有的情况会保留平均值),保持原有的平面结构不变,得到的结果就只有输入的 1/4 大小,这样的做法有点像模糊图像,而之所以保留最大值,是因为我们希望获得的信息是和特定卷积核相似的特征,即能卷积出一个远高于平均值的输入,因此舍弃一些较小值对特征的识别并没有太大影响。
Relu 层
Relu 被称为修正线性单元,是神经元激活函数中最常用的一种。所谓激活函数,就是非线性函数,因为仅用权重、偏差这样的线性函数是没法表示非线性系统的,所以在输出之前往往要加入一个非线性层。
全连接层
全连接层就是一个常规的线性关系,包括系数矩阵、偏置向量。
输出层
对于多分类问题,输出层就是对结果的预测值,一般会加一个 softmax 层,用来将结果在 0-1 上归一化。
对于本次用到的 GAN,输出层就变成了一个图像,也就是一个三维矩阵。
CNN 特点
查阅资料,CNN 相比与传统的神经网络的不同之处主要有三点,分别是局部感知、权重共享和多卷积核。
局部感知
局部感知就是上文说到的感受野,在每个卷积过程中,卷积核所覆盖的像素只是一小部分,是一个局部的特征,即局部感知。所以 CNN 实现了一个从局部到整体的过程,而传统的神经网络是整体全连接的模式。
权重共享
所谓权重共享,其实来自于卷积核的使用,关注核心特征,忽略那些有可能被优化到 0 的、没有信息量的特征,换来了更少的参数。换句话说,使用同一个卷积核在输入图像的各个位置进行卷积,相比于在各个位置使用不同的全连接参数,可以减少很多参数量。
多卷积核
一种卷积核代表的是一种特征,为获得更多不同的特征集合,卷积层会有多个卷积核,生成不同的特征。在卷积的输出处就可以发现,每个卷积核生成了一个独立的通道。当然,即使多卷积核的参数也比实现同样效果的全连接层的参数少。
GAN
生成对抗网络(GAN)于 2014 年首次提出,其最大的特点就是提出了一种让两个深度网络对抗训练的方法。生成器(Generator)将噪声作为输入并生成样本,判别器(Discriminator)从生成器和训练数据接收样本。判别器的目的是区分生成器数据和真实数据。一开始,Generator 将产生一个完全看起来像随机噪声的样本。但是随着时间的流逝,Generator 将学会产生更多逼真的样本。同时,鉴别器还将学习更好地区分生成的数据与真实数据。
判别器
判别器的输入是图像(包括真实的和创造的),输出是一个标量数字,该标量数字描述输入图像的真实度。
生成器
生成器的输入是一个向量,输出是一张图片。按照个人的理解,在训练完毕后,理想情况下每一维的输入都会代表图像中的一个高层语义特征,例如图像中某位置有一个圆、某位置有棱角。
训练
GAN 有两个损失函数,一个使生成器创造更逼真的图片,另一个使鉴别器更好地分辨真实图像。因此判别器的 Loss 包括真实图像计算得到的 Dx 与 1 作差、生成图像计算得到的 Dg 与 0 作差。
判别器最后没有加入激活函数,这是因为鉴别器如果把生成的图片全都打成 0,完全没有梯度可以下降,GAN 就不能训练下去了,这种被称为饱和。
GAN 的训练很难使一对模型的 G 和 D 同时收敛。优化算法通常是个可靠的“下山”过程。GAN 要求双方在博弈的过程中达到均衡。每个模型在更新的过程中(比如生成器)成功的“下山”,但同样的更新可能会造成博弈的另一个模型(比如判别器)“上山”。甚至有时候博弈双方虽然最终达到了均衡,但双方在不断地抵消对方的进步,却并没有使双方同时达到一个总体更优的地方。
TensorFlow
软件平台: Win10 1909、Anaconda 3、Python 3.6.8、TensorFlow 1.14、CUDA 10.0
Coding 的时候,推荐查看官方的 API 手册: https://www.tensorflow.org/versions/r1.15/api_docs/python/tf
使用 TensorFlow 搭建网络的过程中,有几个关键函数及相应参数。
tf.nn.conv2d(
input,
filter=None,
strides=None,
padding=None,
use_cudnn_on_gpu=True,
data_format='NHWC',
dilations=[1, 1, 1, 1],
name=None,
filters=None
)
第一个参数 input 是输入的图像,要求一个四维张量、[batch, height, width, channels];第二个参数 filter 是卷积核,要求一个四维张量、[k_h, k_w, in, out],分别是卷积核的高和宽、卷积需要作用的通道数、输出的通道数(即卷积核的个数);第三个参数 strides 是卷积核移动的步长、[1, s_h, s_w, 1],分别是高度方向和宽度方向;第四个参数 padding,“SAME”补零,“VALID”不补零。
tf.nn.max_pool(
value,
ksize,
strides,
padding,
data_format='NHWC',
name=None,
input=None
)
第一个参数 value 是输入的图像,一般就是上一层 feature map[batch, height, width, channels];第二个参数 ksize 是池化窗口的大小,取一个四维向量,一般是、[1, height, width, 1],因为我们不想在 batch 和 channels 上做池化,所以这两个维度设为了 1;第三个参数 strides 和卷积类似,窗口在每一个维度上滑动的步长,一般也是、[1, s_h, s_w, 1];第四个参数 padding:和卷积类似,可以取“VALID” 或者“SAME”。
语法习惯
使用 TensorFlow 编程时,为了使代码简洁高效,也有一些技巧习惯,学习后总结如下:
节点 op,指基本计算,包括常量定义。会话 Session,调用 Sess.run(关注的 op),会进行所有和 op 相关的运算,获取结果。sess.run 后面可以跟多个张量,同时输出。
矩阵变量名大写,例如权重 W,向量变量名小写,例如偏置 b。
Session 对象在使用完后需要关闭以释放资源。除了显式调用 close 外,也可以使用 “with” 代码块来自动完成关闭动作。
placeholder 的第一维一般设置为 None,这样可以在 session 运行的时候再确定,由此表示可以变化的 batch 大小。
Variable 是可更改的,而 Tensor 是不可更改的。所以 Variable 用于存储网络中的权重矩阵等变量,而 Tensor 更多的是中间结果等。
如果已经存在的变量没有设置为共享变量,TensorFlow 运行到第二个拥有相同名字的变量的时候,就会报错。为了解决这个问题,TensorFlow 提出了 tf.variable_scope 函数:它的主要作用是,在一个作用域 scope 内共享一些变量,简单来说就是给变量名前再加了个变量空间名。此时需要用到 tf.get_variable() 而不是 tf.Variable()。
使用 Tensorboard 可以在训练过程中监视 Loss 曲线、图像输出,使用 FileWriter 创建一个 writer,将需要关注的变量添加到日志,在浏览器对应端口打开即可。
训练
最终设计的网络结构如下(图片使用 ConvNetDraw 工具 生成):
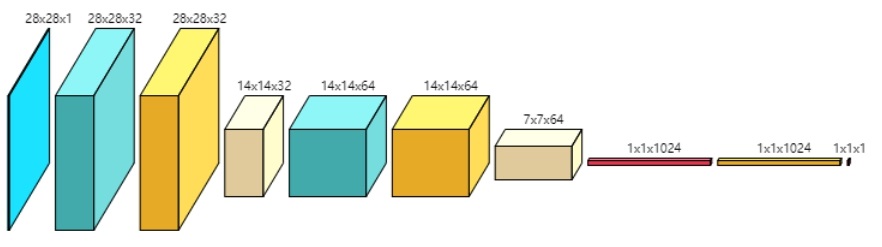 判别器
判别器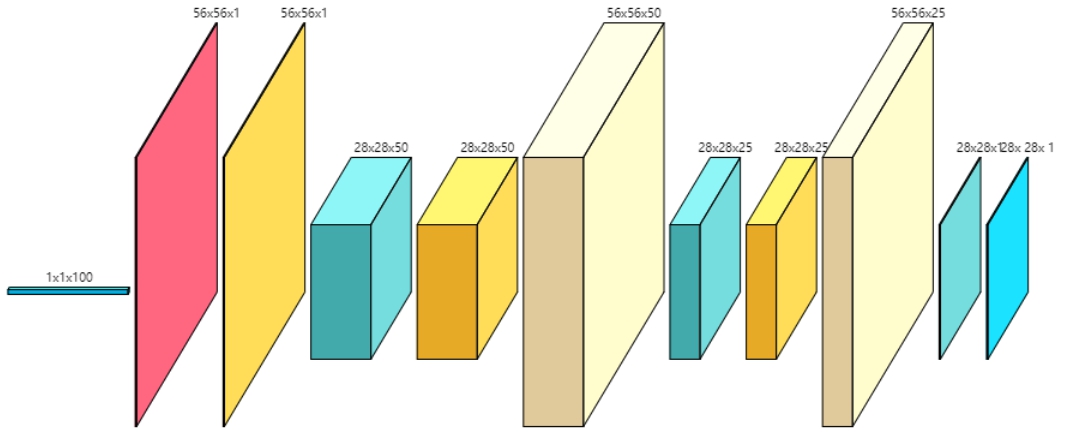 生成器
生成器使用 Tensorboard 跟踪 Loss 曲线,如下。
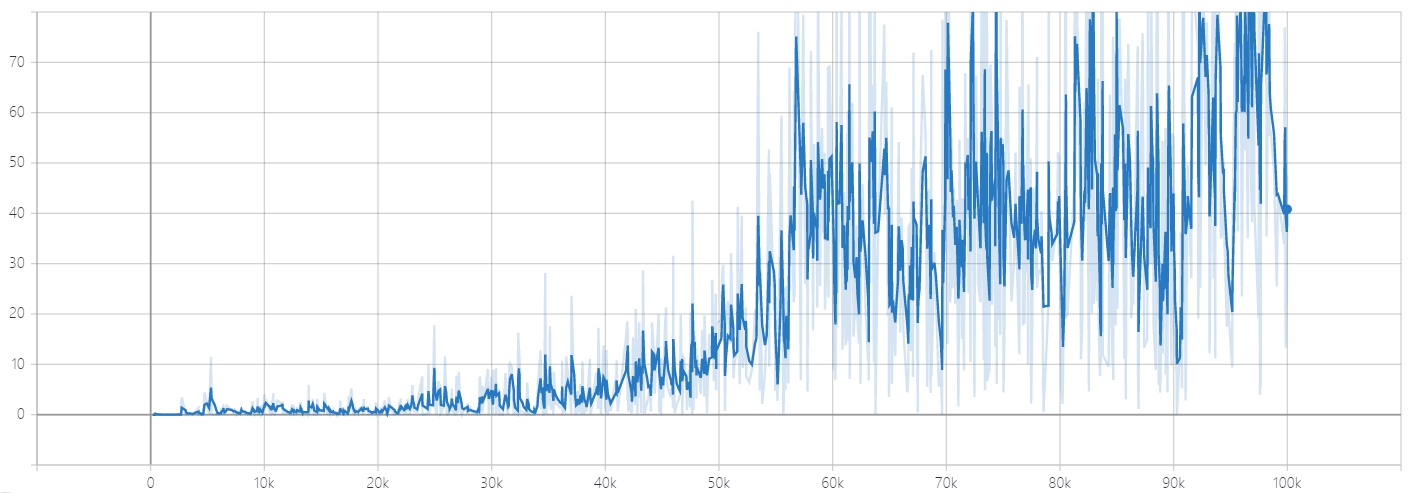 Discriminator Loss for Real Imgaes
Discriminator Loss for Real Imgaes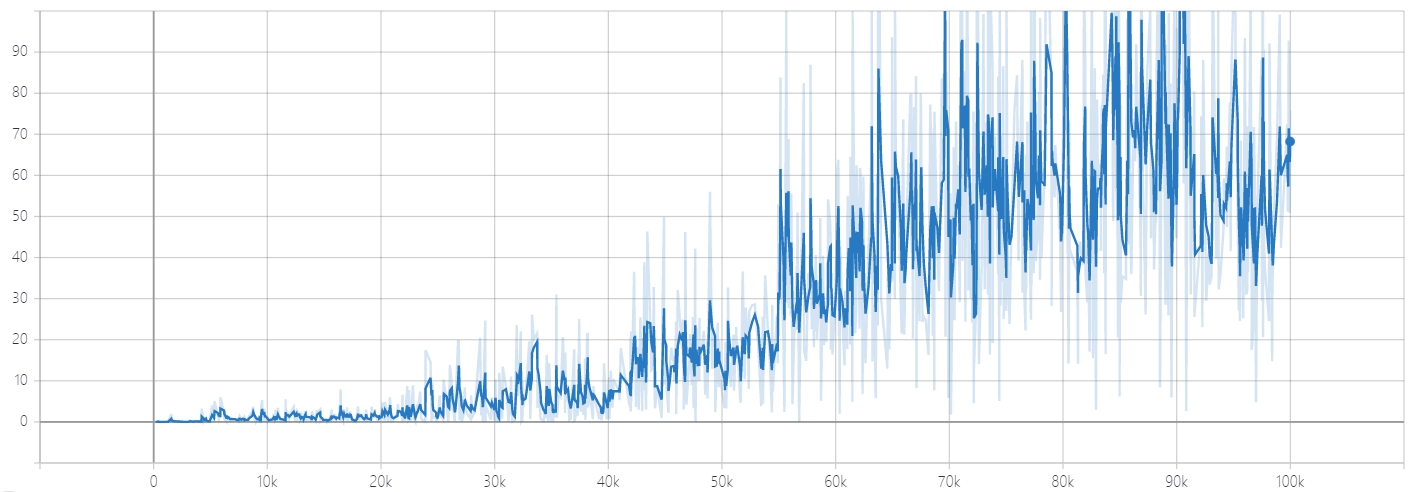 Discriminator Loss for Fake Imgaes
Discriminator Loss for Fake Imgaes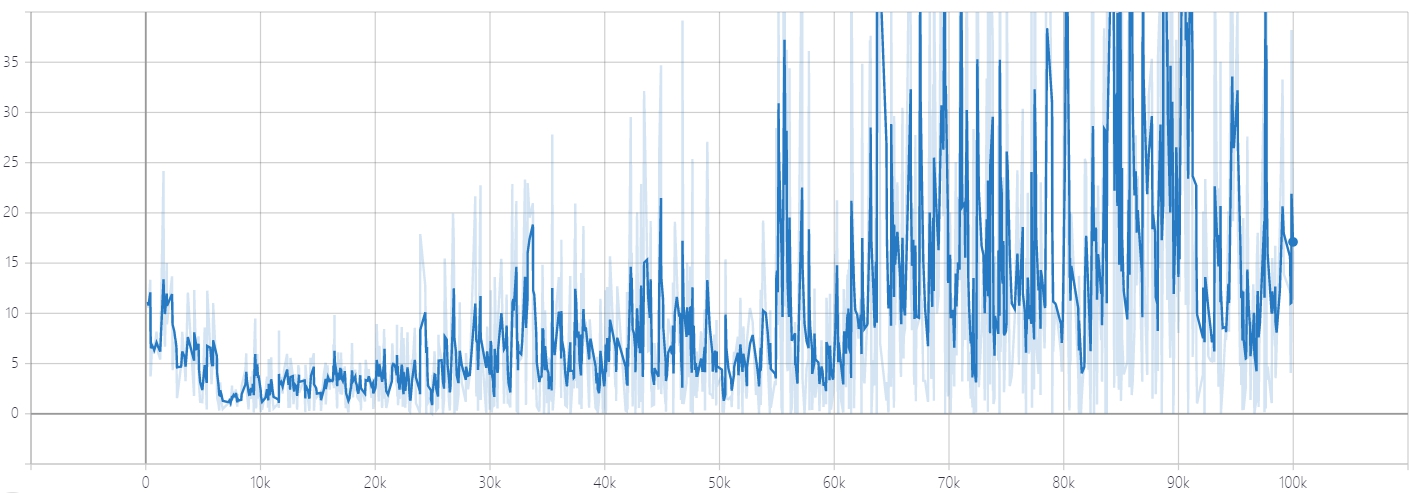 Generator Loss
Generator Loss这时候可以发现,GAN 的 Loss 一直没有收敛。其实不难理解,生成器和判别器的目的相反,也就是说生成器网络和判别器网络互为对抗,Loss 不可能一直降低。如果生成器 Loss 下降快,很有可能是判别器太弱,导致生成器轻易地骗过判别器。若判别器 Loss 下降快,则说明生成器生成的图像不够逼真,才使得判别器轻易判别。
100000 轮后,随机产生一批特征值作为生成器输入,使用网络生成的最终结果如下:

😒差强人意,笔画挺连贯的,但是很难分辨出数字了。多次调整超参数(包括学习率、卷积核数等),效果提升也不太明显。
开源 DCGAN
由于自己构建的网络效果一般,在此基础上,尝试使用开源的 DCGAN 代码 进行学习测试。DCGAN 所提出的模型架构大致如下:
1、生成器和判别器均不采用池化层,而采用(带步长的)的卷积层;其中判别器采用普通卷积(Conv2D),而生成器采用反卷积(DeConv2D);
2、在生成器和判别器上均使用 Batch Normalization;
3、在生成器除输出层外的所有层上使用 RelU 激活函数,而输出层使用 Tanh 激活函数;
4、在判别器的所有层上使用 LeakyReLU 激活函数;
5、卷积层之后不使用全连接层;
6、判别器的最后一个卷积层之后也不用 Global Pooling,而是直接 Flatten。
由于网络环境问题,作者提供的 MNIST 和 celebA 数据集链接都不能正常访问。于是使用 MNIST 官网的数据集,解压之后修改对应文件名,使用作者推荐参数尝试训练。
训练约 5000 轮之后生成的数字如下,考虑到 MNIST 数据集的字体很飘逸(难看),个人认为这样的效果已经相当理想了。