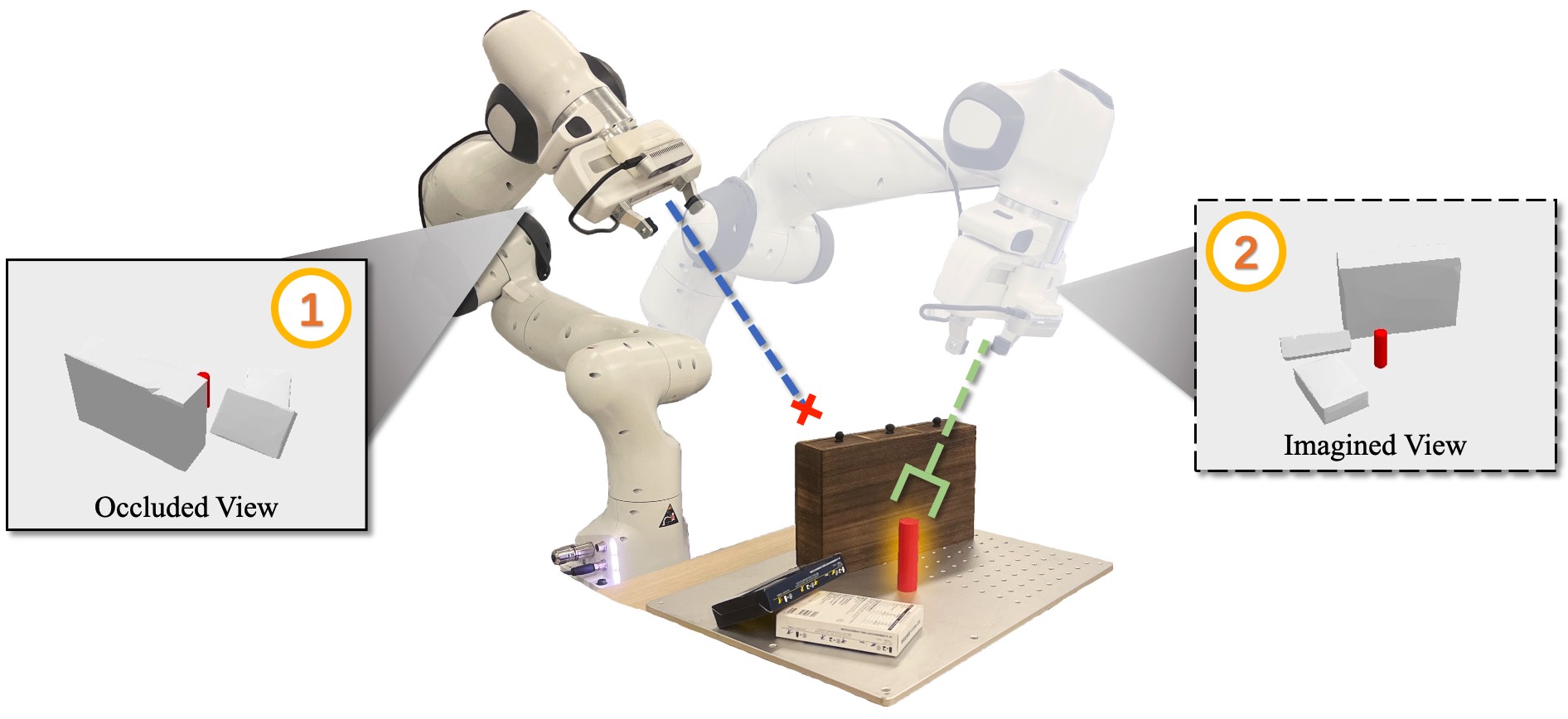
Grasping occluded objects in cluttered environments is an essential component in complex robotic manipulation tasks. In this paper, we introduce an AffordanCE-driven Next-Best-View planning policy (ACE-NBV) that tries to find a feasible grasp for target object via continuously observing scenes from new viewpoints. This policy is motivated by the observation that the grasp affordances of an occluded object can be better-measured under the view when the view-direction are the same as the grasp view. Specifically, our method leverages the paradigm of novel view imagery to predict the grasps affordances under previously unobserved view, and select next observation view based on the highest imagined grasp quality of the target object.
The experimental results in simulation and on a real robot demonstrate the effectiveness of the proposed affordance-driven next-best-view planning policy. Additional results, code, and videos of real robot experiments can be found in the supplementary materials. We present the first method capable of photorealistically reconstructing a non-rigidly deforming scene using photos/videos captured casually from mobile phones.
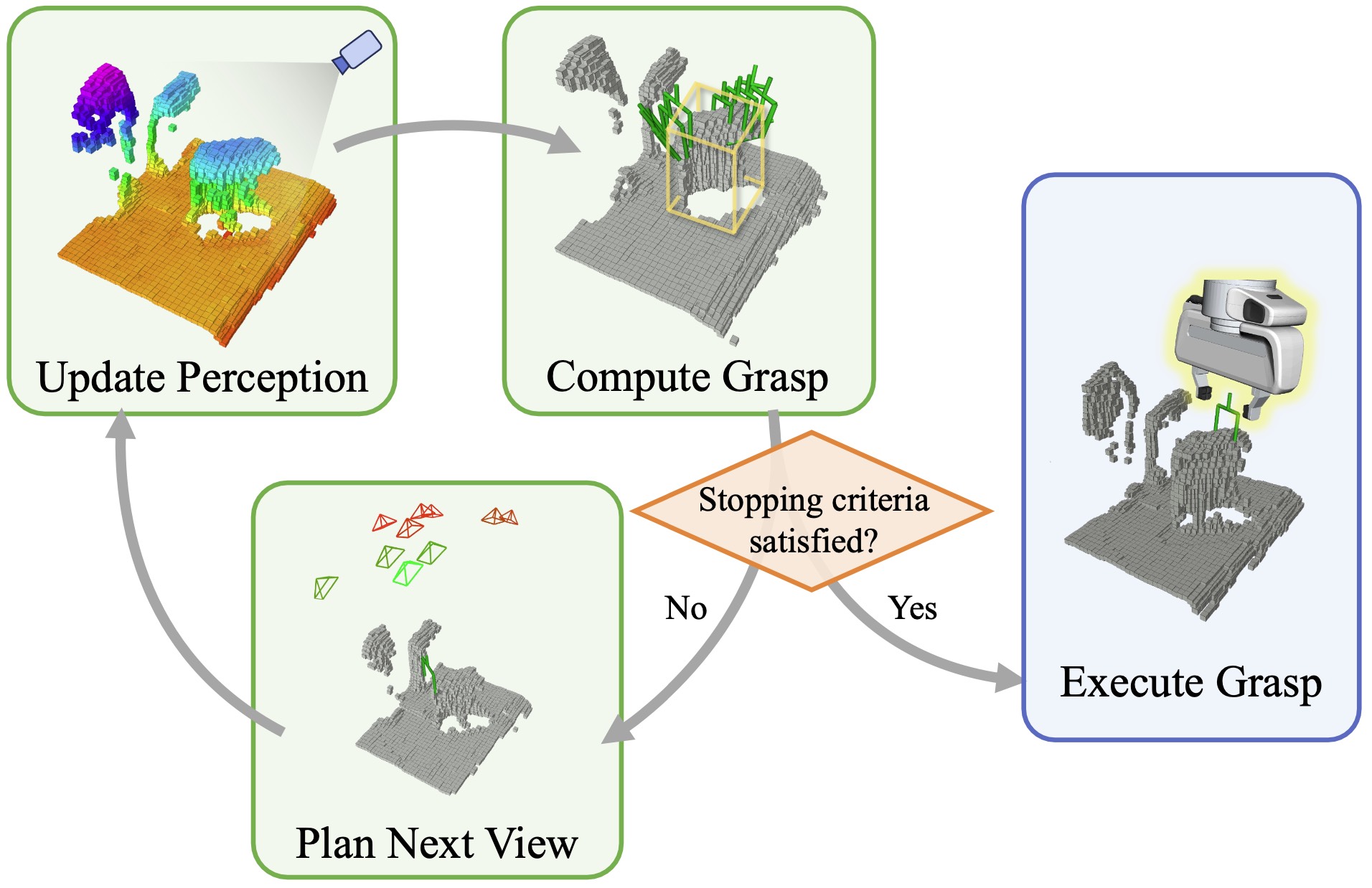
We consider this active grasp problem: picking up an occluded target object in cluttered scenes using a robotic arm with an eye-in-hand depth camera. The target object is partly visible within the initial camera view field and a 3D bounding box is given to locate the target object. Our goal is to design a policy that moves the robotic arm to find a feasible grasp for the target object.
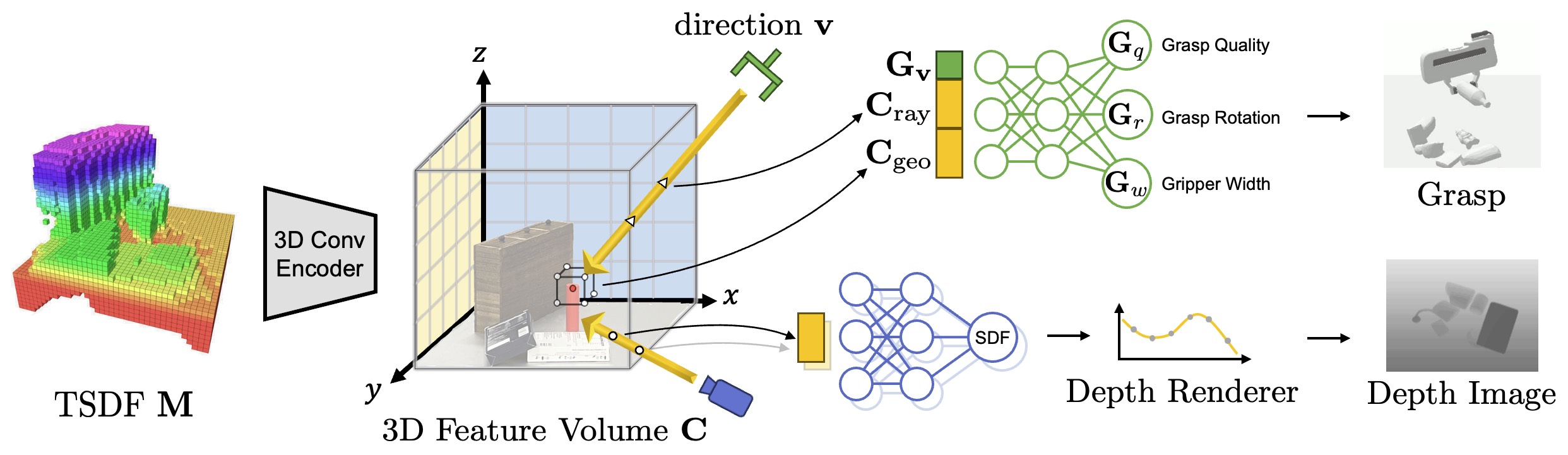
The input is a TSDF voxel field M obtained from the depth image. The upper branch predicts the grasp affordances for the target object and the lower branch synthesizes the depth image of different views, including the previously unseen views. Both branches share the same tri-plane feature volume C.


