HOG 描述子
方向梯度直方图(Histogram of Oriented Gradient, HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。它通过计算和统计图像局部区域的梯度方向直方图来构成特征。Hog 特征结合 SVM 分类器已经被广泛应用于图像识别中,尤其在行人检测中获得了极大的成功。需要提醒的是,HOG+SVM 进行行人检测的方法是法国研究人员 Dalal 在 2005 的 CVPR 上提出的,而如今虽然有很多行人检测算法不断提出,但基本都是以 HOG+SVM 的思路为主。
为了进行图像识别,先要找个办法描述目标物体的特征。亮度、轮廓、颜色、纹理等等都描述着一个物体的特征,其中轮廓应该算是最能代表一个物体的特征,“远处走来一个人”这句话的根据一定是看到了一个人形,而不是因为看到了蓝色衣服。
那么轮廓是一组连续的点集,如何将其中的特征提取出来?一个圆周上的点集,分立来看毫无特征,而与圆心联系起来,就会发现有那么一个公式完美描述了他们之间的关系。同样的道理,也要想办法将轮廓上的点从高维上整理。
HOG 的想法是计算每个像素的梯度,在轮廓上的点明暗变化明显,因此梯度影响也大;接着,通过 cell 和 block 的形式将每个像素的梯度特征合并、串联起来,将每一副图像的轮廓特征都变成大小一致的向量。这样一个向量和 RGB 三维向量一样,也能从一个角度表示一幅图像的属性。
具体地说,一个特征描述子是把一副图像(大小为宽 x 高 x 3) 转化成为一个长度为 n 的特征向量或者数组。在 HOG 中,输入图像大小为 64 x 128 x 3,输出特征向量的长度为 3780。
SVM 分类器
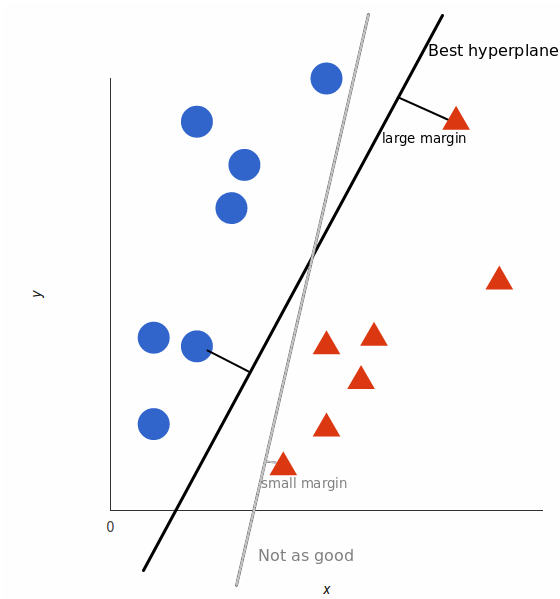
支持向量机,因其英文名为 support vector machine,故一般简称 SVM,通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
有了每幅图像的特征,如何将目标物体和其他物体区分开来?这里使用的是 SVM 分类器。
关于 SVM 分类器有很多优秀的文章,这里不再赘述。试着一句话概括:将待分类的向量放在高维空间中,SVM 算法就是找一个最优的超平面,能够分割开不同的类别,并且满足不同类别到分界面之间的距离都最远。
 详解支持向量机 SVM:快速可靠的分类算法 | 机器之心
详解支持向量机 SVM:快速可靠的分类算法 | 机器之心行人检测实现
数据集
正样本使用的是经过裁剪的 MIT 数据集,同时扩充了一些样本,保证样本框尽可能精确,数量 1173 张。
负样本选择直接在网络上获取,这里使用爬虫在 Google 上搜索了各种主题的无人图像,人工筛去错漏后得到负样本,将其随机分为训练集(522 张)和测试集(80 张)。为了保留真实比例信息并最大化训练效果,训练集中的负样本还需要随机裁剪成 64 x 128 的大小。
最后再单独爬取一些含有人物的图像作为测试集(114 张)。
 正样本
正样本 负样本
负样本算法流程
读取指定数量的正、负样本图像
将正样本图像按比例缩放成指定分辨率的训练用样本
将负样本图像随机裁剪成指定数量的训练用样本
分别计算 HOG 特征,并按顺序加入特征向量序列
开始第一轮 SVM 训练
使用第一轮训练得到的 SVM 分类器对所有的负样本进行检测,将检测出来的行人(假阴)作为困难样本
将困难样本加入原有的负样本序列,进行第二次训练
得到分类器
具体实现
- XPS15 9560 Ubuntu 18.4.03 i7-7700HQ 16.0 GB RAM
- Python.version: 3.6.7 OpenCV.version: 3.4.2
针对不同的训练集规模,综合选择了以下五个有效分类器,对其在测试集中的表现进行对比评估如下,其中 Default 为 OpenCV 自带分类器。
| 时间戳 | 样本规模 (正样本+负样本*分割数) | 重训练样本数 | 训练 开销 | 正例检测为正结果 | 负例检测为正结果 | Precision | Recall |
|---|---|---|---|---|---|---|---|
| 19_32 | 1173+660*100 | 148/660 | 10:43.6 | 30/114 | 3/80 | 90.91% | 26.32% |
| 19_41 | 1173+660*20 | 578/660 | 03:30.2 | 37/114 | 7/80 | 84.09% | 32.46% |
| 19_45 | 500+500*10 | 252/500 | 01:28.7 | 15/114 | 2/80 | 88.24% | 13.16% |
| 20_08 | 200+200*10 | 7/200 | 00:32.8 | 10/114 | 1/80 | 90.91% | 8.77% |
| 20_07 | 100+100*10 | 1/100 | 00:14.9 | 2/114 | 0/80 | 100.00% | 1.75% |
| Default | N/A | N/A | N/A | 101/114 | 31/80 | 71.13% | 88.60% |
由于有没有控制变量,所以五个分类器之间的对比其实没有具体的设计意义,只能大致表现样本总数与训练效果之间的趋势。考虑 Precision 精确度指标时,分类器之间的差异不那么明显;考虑 Recall 召回率的情况下,能体现出样本数带来的优势,但同时发现样本数不断提高后召回率还会下降,猜测这里可能是过拟合的情况;就 Accuracy 准确率来说,少样本的分类器效果明显不佳。
和 OpenCV 提供的默认分类器对比来看,精确度较高但召回率明显不足,这里分析可能是负样本相对数量较多,导致分类边界比较严格。
此外,还测试了使用分类器进行检测的效率,测试集中 194 张图片,分辨率约 500×500pixel,平均每张耗时 0.076446 秒。
下面展示一些离线测试、在线测试的结果。(为了展示效果,输出的结果已经进行非极大值抑制)
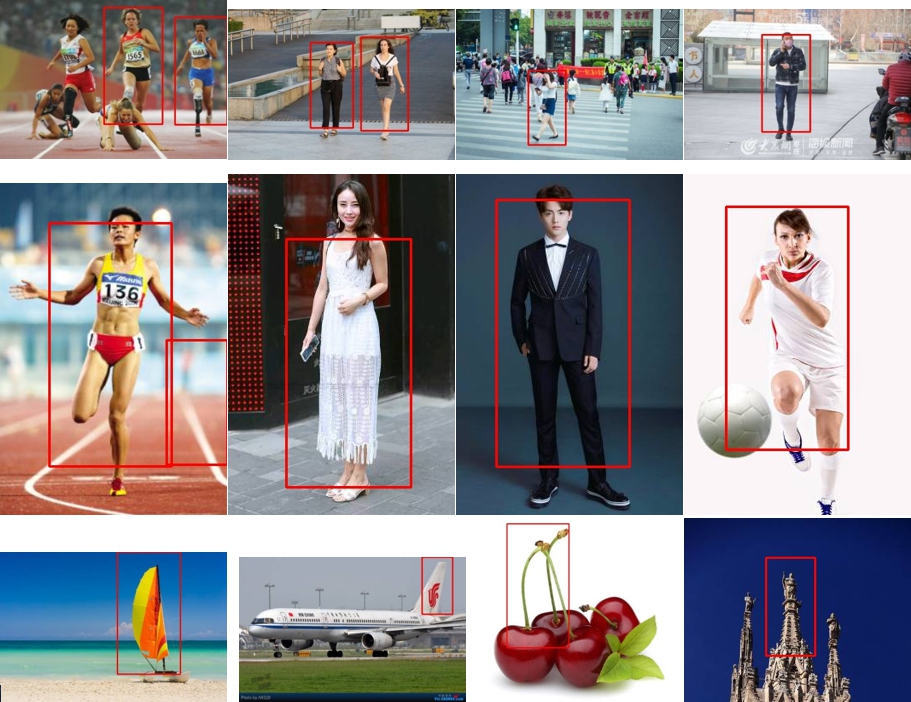 测试结果
测试结果回顾 HOG+SVM 原理也可以理解,这种检测方式只能处理站立姿态、背景无干扰、全身无遮挡的情况,条件比较苛刻。实际检测中甚至不能区分头部特征,而把框画在脖子以下。事实上观察一些误识别的情况,可以发现其都具有类似于人的轮廓特征——竖长形、上方小、下方略有分叉。
传统的图形学算法对于图像的局部特征和全局特征的提取效果还不太理想,底层视觉特性和高层语义概念之间存在巨大的鸿沟,特别是和神经网络提取的特征相比,差距相当明显。