在本学期的《感知与人机交互》小组课程实验中,我选择的是之前从未接触过的语音系统模块。从语音识别的基本原理开始了解,分帧、音素、状态网络训练等概念的学习让我对现在的语音技术有了一定的了解;搭建完整个语音交互系统后,对现阶段已经投入市场运行的一些智能交互系统也有了更深刻的认识,诸如火车站购票系统、医院挂号系统、淘宝智能客服、车载语音助手等等也已不再神秘。
- 主要使用:百度语音识别 API + 百度语音合成 API + 百度 UNIT 理解交互平台
- 工作环境:Ubuntu 18.04 + ROS melodic + Python2
- 3rd party: requests, pyaudio, python-vlc
查阅 ROS 官网 1 后可以看到,ROS 一共提供了五个语音识别库(Audio / Speech Recognition):baidu_speech、hark、pocketsphinx、rospeex、ROSECHO (A Chinese Smart Speaker based on IFLYOS)。综合考虑中文性能、易用性后选择了百度提供的 API。
为了实现较“高级”的人机交互,也尝试了一些智能交互类型的 API,如图灵机器人、百度 UNIT 平台等。由于图灵机器人免费调用的次数非常有限,而且缺少自定义功能,所以最终的选择是百度 UNIT。
为了和实验主线程通信,有如下结构示意图。其中方形是主线程话题,圆形是语音模块节点,虚线表示传输的是使能信号,实线是带有具体信息的信号。
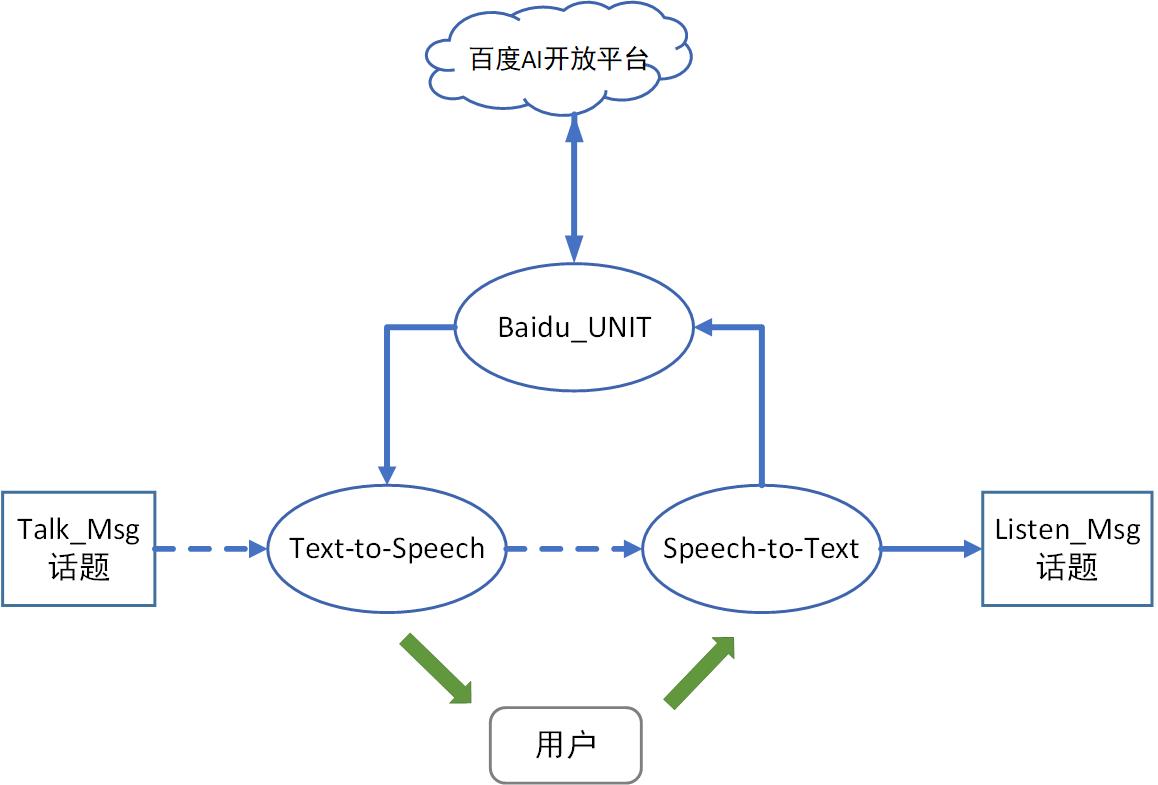 流程图
流程图主要流程是:
- 订阅主线程 topic Talk_Msg,得到主线程通知之后,开始本次对话。
- 调用 TTS 引擎发出提问,播放结束后启用 STT 引擎解读用户语音。
- 同时调用 UNIT API,获取本次对话的 session ID 用于服务器保持本次对话内容,实现多轮对话。
- 重复对话直到获取意图完成,发布 topic Listen_Msg,内容为语音识别的结果,即姓名+物品。
语音合成与识别
处理好网络问题后,顺利安装依赖库文件并 clone 百度语音 API 的相关 demo,初次运行时提示 print 附近有报错,怀疑是之前安装的 Anaconda 与 ROS 下的 Python 版本冲突,于是把。bashrc 里面的 anaconda 先注释了,确保调用 python2,暂时解决这个兼容性问题。
此 API 需要在百度开发平台先注册功能,并获取相应的 API Key、Secret Key。首先测试百度语音合成 API 的功能,使用命令rostopic pub /speak_string std_msgs/String '你好世界'向 TTS 节点发送 string 类型信息,成功调用了 TTS 引擎,扬声器正确发出声音。此外,API 还支持不同的语速、音调、音量、性别,可以按需进行调整。但是需要注意的是语音合成的音量非常轻,默认参数下很难听到,导致一开始误以为合成失败,当然也可能是个人硬件问题。
然后是语音识别部分,第一次启动提示报错:Value for header {Content-length: 183} must be of type str or bytes, not <type 'int'>。之后在 GitHub issues4 找到了答案,应该是百度 API 的格式有变化,rate 参数的类型从 int 变成了 string,检查百度官方文档后可以确定这一问题,修改即可。
之后 demo 程序可以正常启动,按照流程说话采集后陆续报了如下几个错误代码,但都在官方接口文档 5 上找到了解答。
| 错误码 | 含义 | 一般解决方法 |
|---|---|---|
| 3301 | 识别结果实际为空 | 可能是音频质量过差,不清晰,或者是空白音频。 有时也可能是 pcm 填错采样率。如 16K 采样率的 pcm 文件,填写的 rate 参数为 8000。 |
| 3314 | 音频长度过短 | 用户的 len 参数小于等于 4。 |
然后测试 STT 节点功能,启动后响应回车键,麦克风开始录音,当录制到的声音小于一定阈值时,停止录音,并可以将音频文件发送至云端进行识别,最后将结果返回客户端。
实际的语音识别效果受到多种因素影响,其中录音环境是最重要的一个因素,当人声清晰、无背景噪音的时候,识别效果非常好,若存在背景噪音,例如电脑风扇声等,都会很大程度地影响识别效果。
此外,待识别的语句如果存在生僻字,识别效果也会打折扣。针对生僻专有名词的场景,百度提供了自定义词库来快速提升对应名词准确率,或者可以通过语音自训练平台训练专属模型持续提升识别准确率。
值得一提的是,百度官方示例程序中,竟然出现了simple_speek.py这样的文件名,不知道是笔误还是审核疏忽。
智能交互
UNIT 是百度的一个智能交互理解平台,期望实现“面向任务”的理解与交互能力,这里的一项任务可以是解答用户的某个问题、执行用户指令,甚至通过一系列交互引导用户达成某项需求,其官方使用场景有:酒店语音助手、儿童故事机、火车票场景、查天气机器人等。
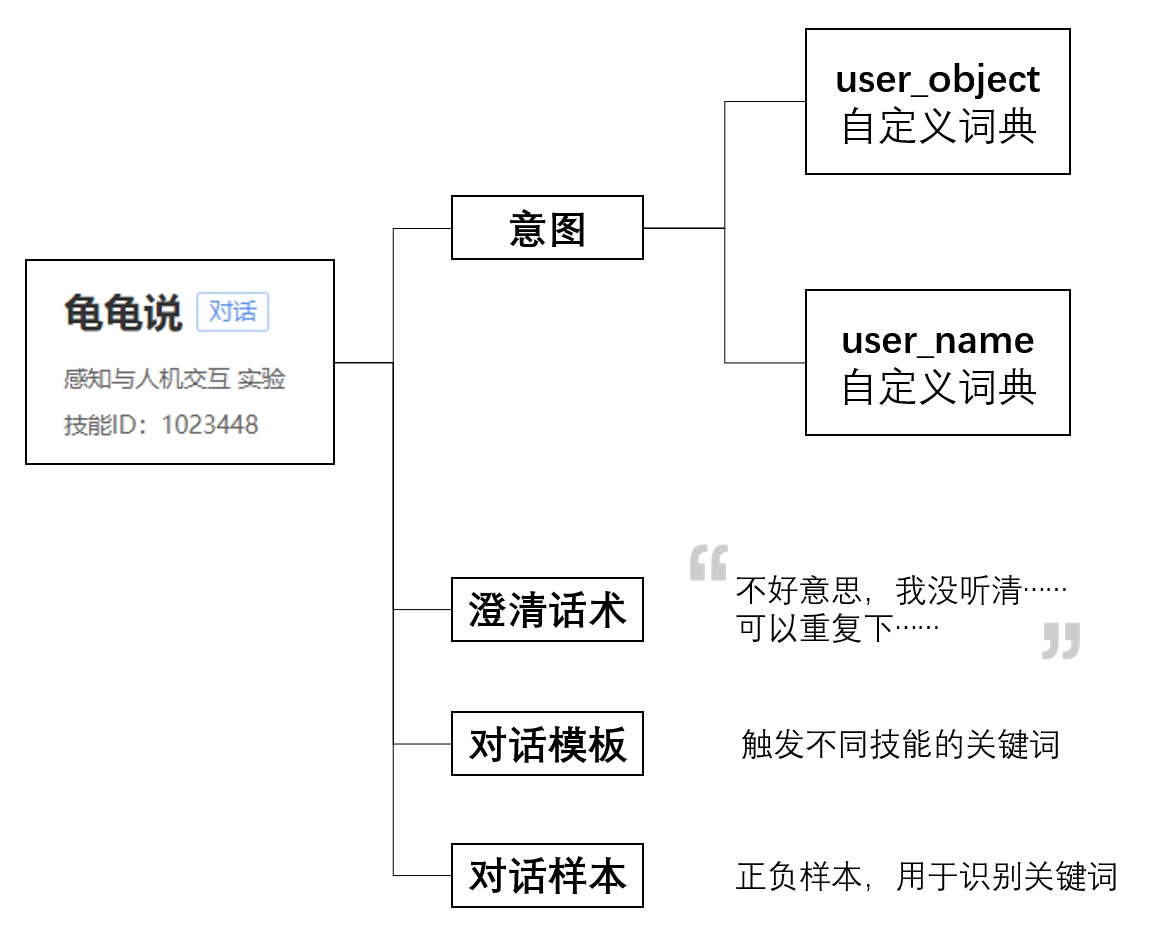 百度 UNIT 结构
百度 UNIT 结构这次在 UNIT 上搭建了一个“你要拿什么”的技能,对应设置了 name 和 object 两个词槽,并上传了自定义字典。配置了不同词槽的澄清话术,并设置了对话模板,然后导入样本集进行训练,最后顺利部署这一技能,获取到技能 ID。
接着测试 API 功能,按照官方文档给出的 json 文件格式写好数据包,请求参数中有一项 query_info→source,请求信息来源,可选值:“ASR”,“KEYBOARD”。ASR 为语音输入,KEYBOARD 为键盘文本输入。针对 ASR 输入,UNIT 平台内置了纠错机制,会尝试解决语音输入中的一些常见错误。由于之前已经单独配置了语音合成与识别节点,所以这里就先使用文本输入。
配置好 API Key、Secret Key、机器人编号、技能编号之后,在 ROS 下进行相应的 API 测试,整理完节点之间的逻辑关系后设置了几个话题:/UNIT_Listen、/speak_string、/TTS_LastWord,配合自己模拟的主线程进行测试。实际测试结果是多轮对话一直失败,服务器返回的 session-ID 一直无法保持。
后来使用 Ubuntu 下的网页 API 测试工具 Postman 进行本地 API 调试,可以看到 UNIT 平台正常返回了对话数据,手动保存返回的 session ID 之后,加入到发送的 json 中,可以成功实现多轮对话的功能。
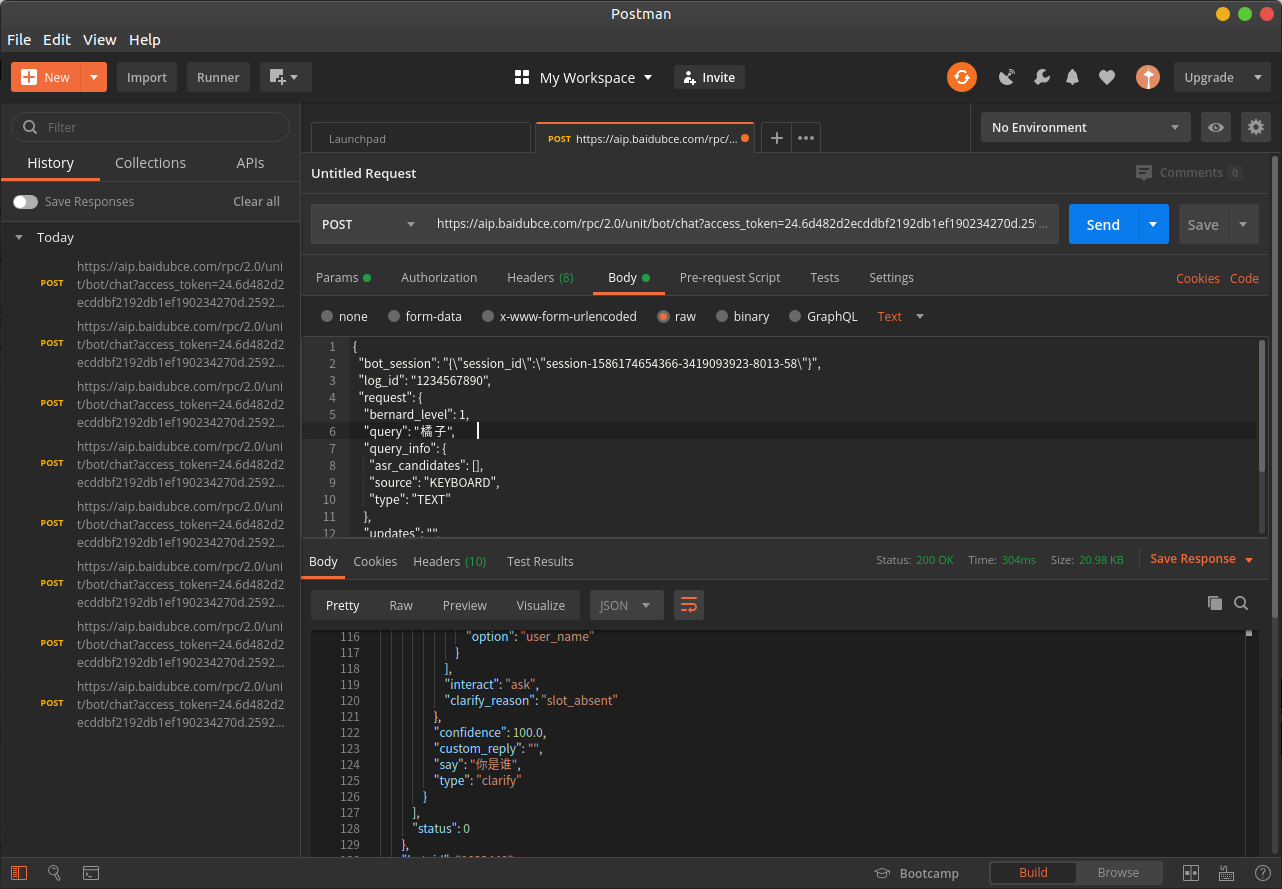 Postman
Postman因此开始仔细对比两边的 json 数据包,最后发现是 Python 中编写 json 格式字符串时,没有注意转义符与换行符,json 字段中需要保留的双引号存在嵌套的情况,没有特殊处理导致有效内容被转义了,于是数据包发送失败。
由于对 json 文件格式、Python 语法不熟悉,这个问题花费了相当长的时间,使用了 API 测试工具 Postman 之后提高了工作效率,也更容易地发现了 bug 所在。修复之后重新开始测试,最终效果基本能到达预期要求。
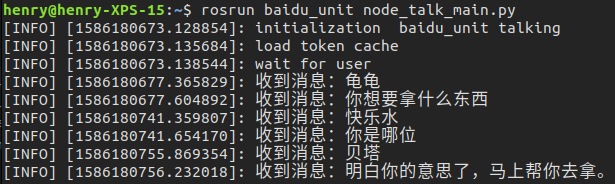 效果图
效果图以下是三个实际运行的案例文字版,分别表现了正常获取意图、重复澄清、整句获取三种场景功能。
发送消息:请问有什么可以帮你? 正在录音。.. 收到消息:帮我拿杯快乐水。 回复消息:你叫什么名字 正在录音。.. 收到消息:我叫小明。 获取意图:小明想要可乐。明白了,马上就去拿。
发送消息:请问有什么可以帮你? 正在录音。.. 收到消息:龟龟,帮我拿个东西。 回复消息:不好意思,需要我帮你拿什么 正在录音。.. 收到消息:水杯。 回复消息:你叫什么名字 正在录音。.. 收到消息:张三。 获取意图:张三想要水杯。明白了,马上就去拿。
发送消息:请问有什么可以帮你? 正在录音。.. 收到消息:我是玛丽,帮我拿一包泡面。 获取意图:玛丽想要方便面。明白了,马上就去拿。
那么最后,总结一下,本次实验调试并接入百度语音合成与识别 API,配置相关参数;在百度 UNIT 理解交互平台上搭建对话技能,对应要求建立相应字典,完成较高容错率的交互功能;整合上述两部分功能并与主线程通信,学习了一些调试技巧。本次涉及到的语音部分代码已托管在 Github 平台。